Contents
ComfyUI 란?
ComfyUI는 스테이블 디퓨전(Stable diffusion) 모델의 요소들을 노드로 표현하여 생성, 연결하는 워크플로우를 제공하여 쉽게 이미지를 생성할 수 있도록 돕는 노드 기반의 GUI(Graphical User Interface) 도구입니다. 코드를 직접 작성할 필요가 없으며, 노드들의 연결만으로 스테이블 디퓨전을 이용할 수 있습니다. 그리고 데이터 흐름을 직접 볼 수 있어 사용자들에게 편리한 환경을 제공하고 워크플로우를 저장하고 불러 올 수 있어 워크플로우의 관리도 편리합니다. 위에 언급된 스테이블 디퓨전은 ComfyUI에 있어 중요한 부분이므로 간략하게 알고 넘어가겠습니다. Stability AI(Emad Mostaque가 설립한 회사)에서 독일 뮌헨 대학교 Machine Vision & Learning Group (CompVis) 연구실의 “잠재 확산 모델을 이용한 고해상도 이미지 합성 연구”를 기반으로 Runway ML와 공동 개발한 것을 오픈소스 라이선스(CreativeML Open RAIL-M License)로 배포한 text-to-image 인공지능 모델입니다. 많은 이미지 생성 AI가 온라인으로 서비스를 제공(OpenAI의 Dall-e 2, 구글의 Imagen 등)하는데 반해, 스테이블 디퓨전은 개인 PC에서도 실행 가능하도록 컴퓨터 리소스 사용을 대폭 줄여 개발 되었습니다.
기본 구조
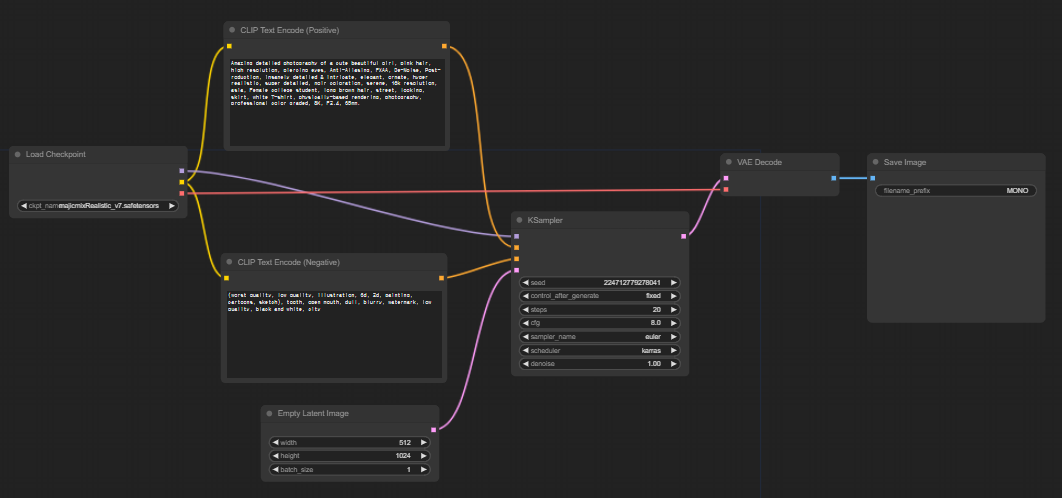
ComfyUI의 워크플로우는 노드(node)와 엣지(edge)로 구성되어 집니다. 노드는 아래의 그림에서 볼 수 있는 Load Checkpoint, Clip Text Encode, KSampler, VAE Decode 등의 박스들을 일컫습니다. 노드는 입력과 출력 인터페이스를 가지며 상자 내부에 보여지는 파라미터(설정) 값을 가집니다. 그리고 이들 노드와 노드를 연결하고 있는 선들을 엣지라고 부릅니다. 엣지는 노드의 흐름을 제어 해 준다고 보시면 됩니다.
Load Checkpoint
워크플로우의 시작은 체크포인트를 설정하는 것으로 부터 시작합니다. 체크포인트는 스테이블 디퓨전에서 사용할 모델을 선택하는 것입니다. ckpt_name 파라미터의 모델명을 클릭하면 사용 가능한 모델의 목록이 표시되며, 그 중 하나를 선택하여 모델을 적용할 수 있습니다. Load Checkponit node는 잠재 공간에서 노이즈를 예측하기 위한 모델(MODEL)과 긍정/부정 프롬프트를 처리하는 클립(CLIP) 그리고 픽셀과 잠재 공간 사이에서 이미지를 변환해주는 배(VAE)로 구성됩니다.
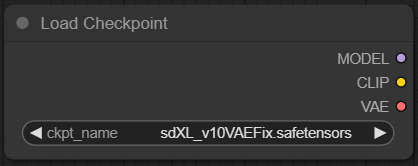
MODEL : 잠재 공간의 노이즈 예측 모델이며, 스테이블 디퓨전에서는 U-net이라는 모델을 사용.
CLIP : 긍정/부정 프롬프트(CLIP Text Encode (Prompt))와 연결.
VAE : 가변 자동 인코더로 픽셀을 잠재 공간 이미지로 변환.
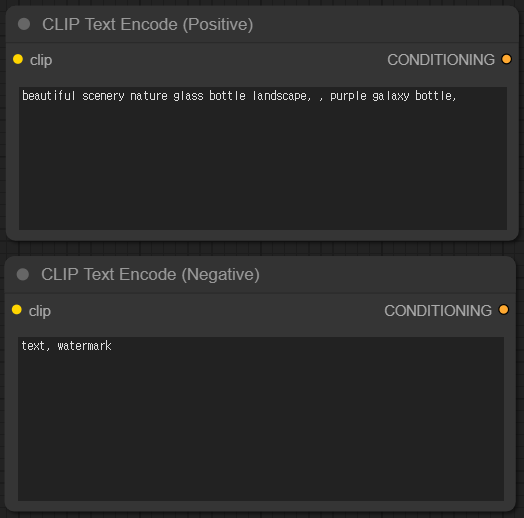
CLIP Text Encode (Positive/Negative)
CLIP Text Encode 노드는 입력된 프롬프트에서 단어를 추출하고 해당 단어들을 CLIP 언어 모델에서 매칭된 토큰으로 변환합니다. CLIP Text Encode는 긍정과 부정의 두개의 프롬프트를 입력 받습니다. 긍정(positive) 프롬프트는 생성되는 이미지에 포함되어야 할 내용들이며, 부정(negative) 프롬프트는 이미지 생성시 제외되어야 할 내용들을 입력합니다. 그리고 작성된 각각의 프롬프트는 KSampler 노드에 positive와 negative에 맞게 연결을 해주시면 됩니다.
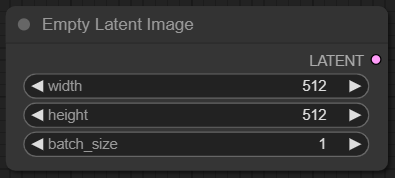
Empty latent image
Empty latent image 노드는 잠재 공간(latent space)에 빈 이미지 공간을 생성합니다. 이때 노드에 설정된 latent image의 크기와 동일하게 잠재 공간이 생성됩니다. 그리고 batch_size라는 필드에 값에 따라 한번에 생성할 이미지의 갯수를 지정할 수 있습니다. 여기에 10을 설정하면 한번에 10장의 이미지를 생성합니다.
KSampler
KSampler는 잠재 공간의 이미지에서 아래의 설정한 값에 의존하여 노이즈를 제거해 가는 과정을 반복합니다.
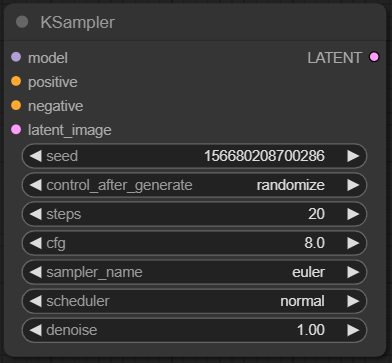
파라미터는 아래에 내용과 같은 기능을 수행합니다.
- seed : 무작위 시드 값은 잠재 공간 이미지의 초기 노이즈와 최종 이미지의 구성을 컨트롤 합니다.
- control_after_generate : 초기 시드를 설정합니다. 랜덤하게 임의의 값을 지정하거나 시드를 고정하여 사용할 수 있습니다.
- steps : 샘플링하는 단계의 수입니다. 생성된 이미지의 남은 노이즈 제거 정도에 따라 단계의 수를 증가 또는 감소 시켜 주어 적절한 값을 주어야 합니다.
- cfg : 프롬프트 적용에 대한 자유도 입니다. 높은 값을 입력하면 프롬프트의 내용을 지키려는 확률이 높고, 낮추게 되면 무시하려는 확률이 높아집니다.
- sampler_name : 샘플링 알고리즘을 설정합니다.
- scheduler : 각 단계의 노이즈 변경 방법을 제어합니다.
- denoise : 초기 노이즈를 얼마 만큼 줄지를 설정합니다. 1.00인 경우 잡음이 최대로 추가 됩니다.
이 node에서는 잠재 이미지(latent image)를 샘플링하여 생성합니다. 잠재 이미지를 실제 이미지로 변경하려면 LATENT와 VAE Decode를 연결하여 줍니다.
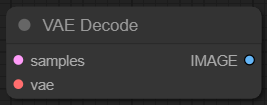
VAE Decode
VAE(가변 자동 인코더, Variable Automatic Encoder) Decode 노드는 잠재 이미지를 실제 이미지로 바꾸어 줍니다.
Save Image
마지막으로 VAE Decode를 통해 생성된 실제 이미지를 저장하는 노드입니다. filename_prefix는 생성될 파일명이며, 생성된 순서에 따라 prefix명에 순차적 숫자가 부여되어 파일이 저장됩니다. 저장되는 경로는 comfyui가 설치된 경로의 output 폴더에 저장이 됩니다.